API Coordination
Problem
You have implemented a microservices architecture and are now facing the challenge of upgrading from a legacy service to a new service without downtime or migration. Due to the lack of control over client versioning, you need to support multiple versions of the API simultaneously.
While it is possible to implement system-to-system synchronization, it introduces significant infrastructure requirements from the outset and leads to a drastic increase in complexity to accommodate the preservation of services across various client versions.
Solution
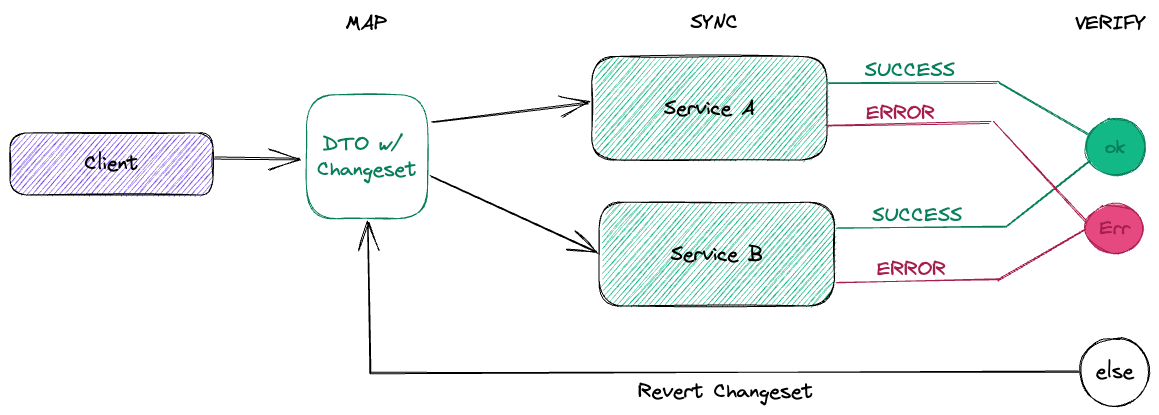
To address the issues present in the legacy pattern, we propose a new solution called "API Coordination", which consists of the following steps: Map ⇒ Sync ⇒ Verify.
-
Map: Map the shared data from the microservices into a Data Transfer Object (DTO) that can be used for synchronization.
-
Sync: Call the respective API operations in both microservices, passing the mapped DTO data to be synchronized.
-
Verify: Ensure that both API operations succeed. If any operation fails, use the DTO to revert the data to its original state or throw an exception if the revert API call also fails.
This approach reduces infrastructure complexity by eliminating the need for additional architectural components, improves data consistency by incorporating a verification step, and mitigates the risk of data drift causing business or operational failures.
It's important to note that this solution may not be necessary in an Event Sourced system, where data models are derived from aggregates, or in cases where data drift is not a concern. However, for many scenarios, the "Map ⇒ Sync ⇒ Verify" process can provide a more efficent and manageable way to synchronize data between microservices than other approaches.
Failure in the reversion step can be handled by the client, which can retry the operation or notify the user of the failure. The client can also choose to ignore the failure and continue with the operation, which may result in data drift. However, in many cases this is an acceptable tradeoff, as failures upstreams are often minimal. We call this approach "Optimistic Consistency".